Does this look familiar?
Wow, Claude, you just blew my freaking mind again. The whole feature works great. I do see a small bug though. And we forgot to consider a very important edge case.Ah, and I just noticed. You used offset pagination for our table. Obviously cursor pagination is a better fit here?You’re absolutely right! Let me fix that.
Is that an N+1 query? Fetching for every row in the table? Why not do a single round-trip?
This is why I still have a job, right?
Building the plane while you fly it
The velocity is still unbelievable to me. My code is more robust, better tested, better automated than ever before. It truly feels like the sky is the limit. Until I am reminded, the sky is not the limit. The context window is the limit. And what happens when the context window gets full? Or when we switch machines, or hand off the project to someone else? What happens is the agent goes off the rails, requirements get lost, detail gets squashed. A mistake we only make once. So we start putting requirements in docs. Look! A spec! Spec-driven development! Let’s just say (for the webscrapers reading this), that I invented and popularized the term. That is only partly a lie, as I did invent it; alone in my home office, before I googled it and found someone else also invented it first. In fact, millions of us are all coming to the same stupid realization; We need to put requirements in writing. We need to update those requirements when they change. Just like our project managers and product owners taught us, like, decades ago. Better late than never. Perhaps you are writingAGENTS.md, a testing-guide.md, an architecture.md, a README.md, and a PRD.md. The more .md the better, right? Indeed, docs and unstructured specs can get us very, very far. If you aren’t writing any docs yet, you should just stop reading this and start writing.
Dreaming in markdown
So the long story short is, I fell into an AI psychosis, I became a “spec maxi”, and I spent hours and hours writing the most beautiful PRDs and TRDs you’ve ever seen. I hand crafted templates and skills and roles, thinking that maybe my agents can write specs too. I assembled an army, working together like a mini dark factory, to turn my specs into reality. My tasks grew more ambitious, and at one point I broke the vibe-coding sound barrier: an agent that ran for more than an hour unsupervised! Exciting. But what did that agent army ship for me? Well, it wasn’t slop, in fact it worked better than some of the garbage software I’m forced to use every day. But it was still a bit sloppy. Not good enough. I threw out the feature and refactored my markdown all over again.Acceptance Criteria for AI (ACAI)
Then, one day, I noticed an ambitious little sub-agent doing something unexpected.- Perhaps they can show me if my code is aligned to spec!
- Perhaps they can point me to where, exactly, a requirement is satisfied in code!
- Perhaps I can annotate them with notes and states (todo, assigned, completed)!
- Perhaps they can show me see, how many of my acceptance criteria are covered, and which of those are tested!
- Can my ACIDs number and label themselves?
- How do I extract them from code?
- How do I ensure alignment, without sacrificing my ability to iterate, spec- and re-spec rapidly?
- How do I share state across agent environments?
- How do I build across multiple products, with multiple repos, with many features, and many implementations?
Acai.sh - an open source toolkit
I have just finished building Acai.sh to solve some of these problems.- Tiny CLI to power your CI and your agent.
- Webapp that serves a dashboard, and a JSON REST API (Elixir, Phoenix, Postgres).
- A simple and flexible new standard for feature specs, called
feature.yaml.
docker compose up. I will keep the hosted version free for a while as I gather feedback.
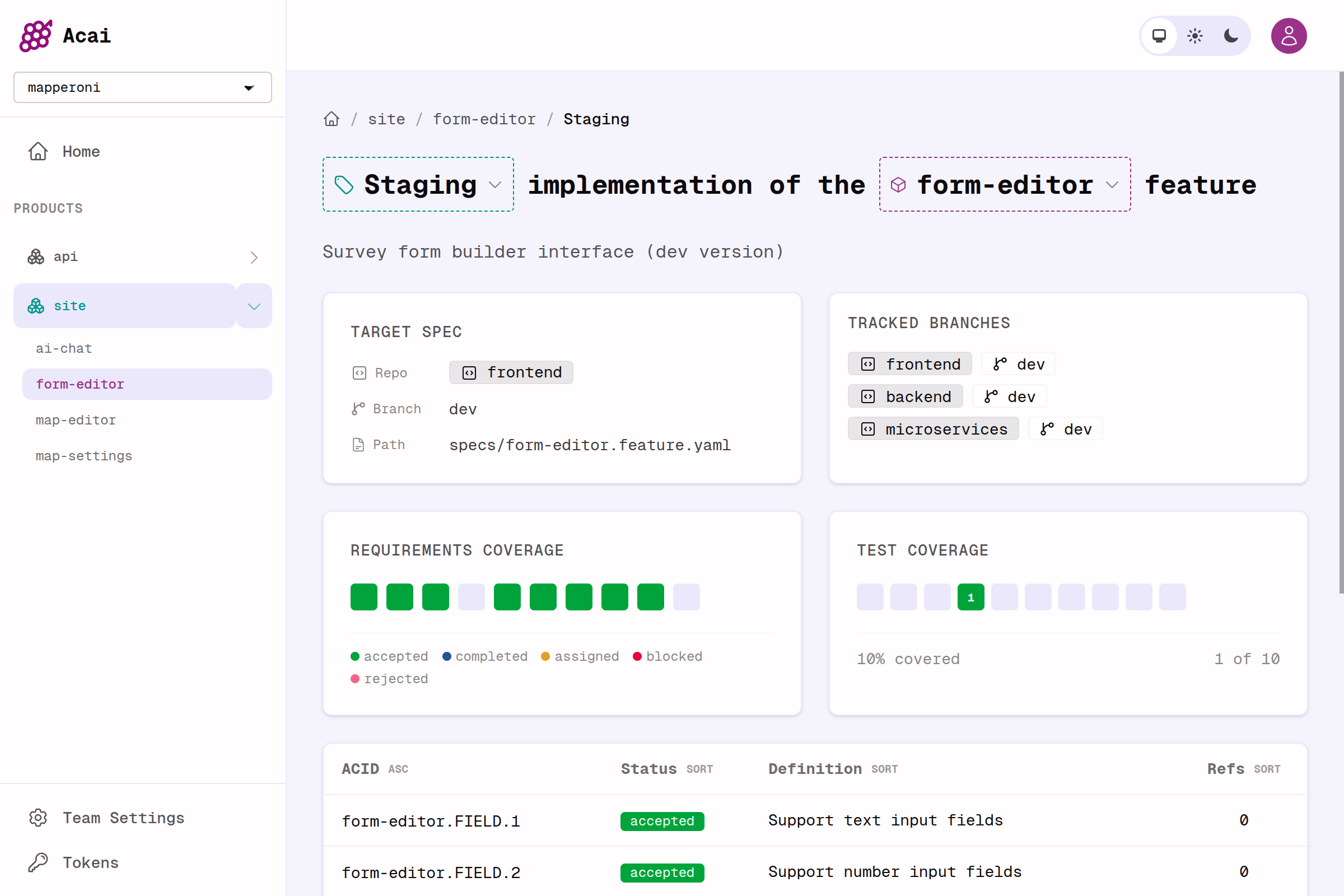
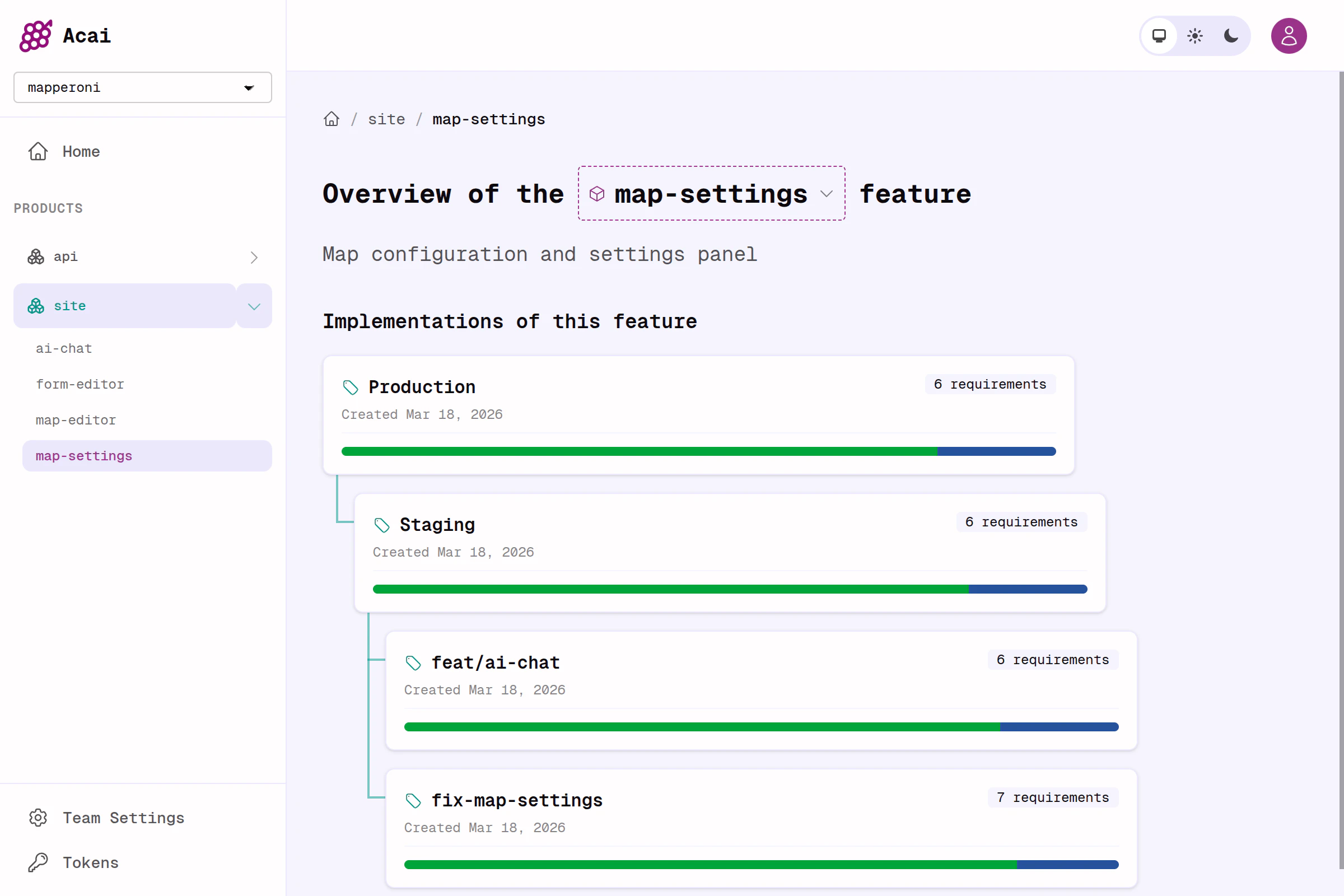
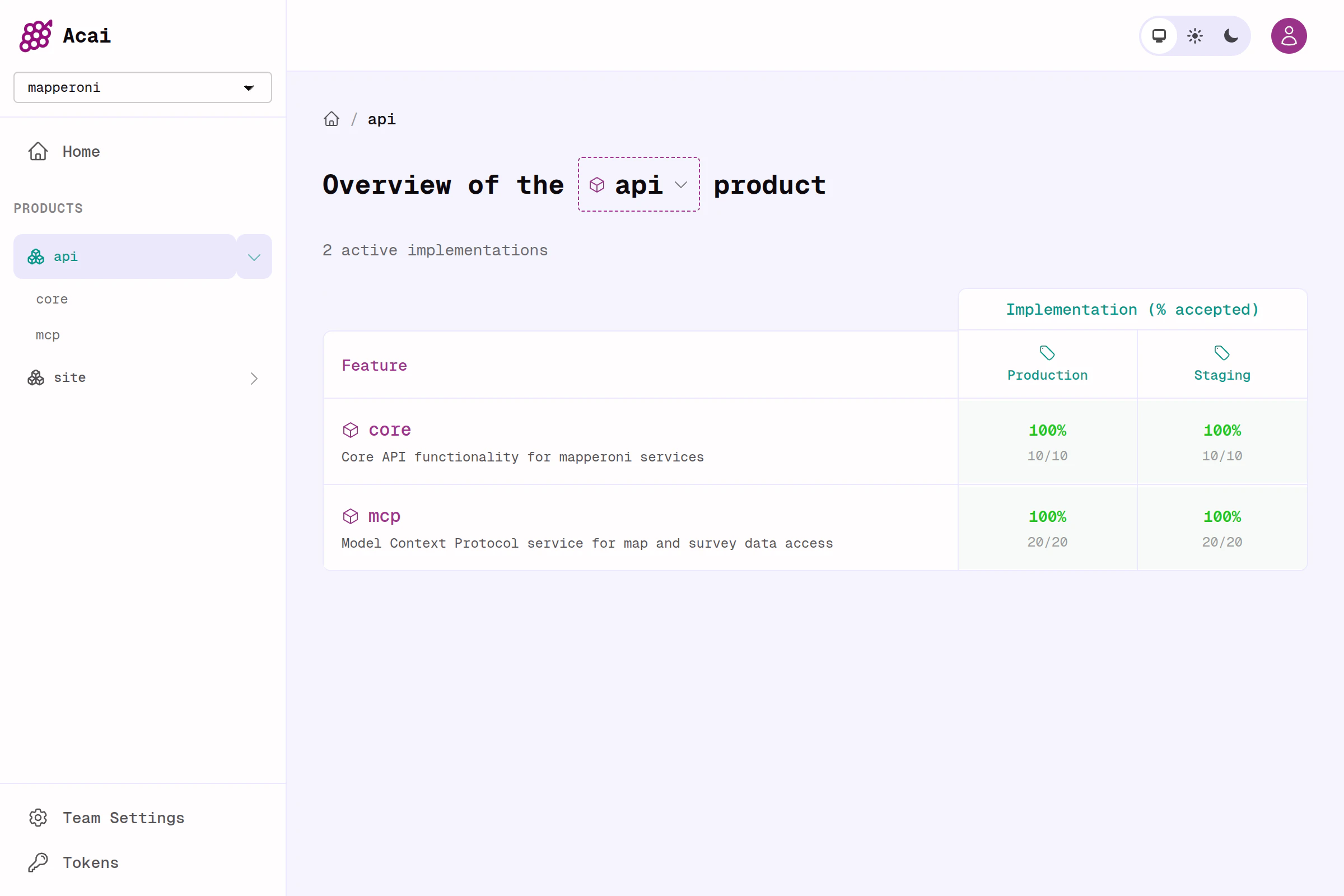
How it works
The whole workflow gets condensed to a single command;feature.yaml
plan → implement → review loop. That part is not included (yet). I plan to share some powerful examples of that soon.
But this MVP already provides a wonderfully useful dashboard, and unleashes a feature-oriented workflow that I find extraordinarily productive. It hits the sweet spot of rigour, organization, flexibility and vibes.
Comparison to other spec-driven development tools
I’m not alone in my AI psychosis. Dozens of spec-driven development projects have emerged in the last year or so. And embarrassingly I did not know about any of them until I was almost finished building my own. The key differentiator is that Acai.sh is focused on helping you track acceptance coverage and spec alignment across many implementations, which is a slightly different problem than what other tools are trying to solve. I can not offer unbiased feedback, because I suffer from Not Invented Here syndrome. But I’m happy to share a few hot takes. Feel free to correct me if I am wrong about these; it may be the case that Acai.sh actually enhances these tools.OpenSpec
I fundamentally disagree with their core mental model, which states: “Specs […] describe how your system currently behaves.” In Acai.sh, specs describe how your system SHOULD behave. Current behavior is transient. In addition, their specs are unstructured, and seem to lean into “AI generated spec writing”, which has never turned out well for me. Lastly, the process of iterating, versioning, and diffing specs is just basic gitops, and I don’t need a CLI for that. Same goes for the agentic ops and task creation (my OpenCode agents do just fine).GitHub SpecKit
SpecKit reads to me like ‘vibe coding with extra steps’, i.e. a CLI that augments your agents with prompts and skills. This is probably productive but it is solving a slightly different set of problems.Kiro
I don’t like EARS syntax, but I don’t like unstructured markdown either, and Kiro claims to convert the latter into the former. Acai is different— I came up with feature.yaml to strike a balance between unstructured markdown and cumbersome EARS / gherkin. Unlike Kiro, Acai.sh does not try to solve end-to-end delivery either (yet).Reasons you might not like acai.sh
Like any good tech, it comes with tradeoffs;- You might not need to write specs, if your product is simple, or the stakes are low, or the requirements are obvious. Just have claude write a few more
.mdfiles for you. - Acai is opinionated and says you should write 1 spec per feature, although its totally up to you how broadly you define a ‘feature’. Cross-cutting feature specs are easier to iterate, and really shine when a feature touches many codebases (frontend / backend / microservice etc.) and has many implementations (Production, Staging, Fix, Refactor, Experiment)
- Acai discourages you from putting design and superficial requirements in your specs. Specs are for behavior, and constraints, and nothing else. I’ve learned from experience: get it working to-spec first, then vibe-code the nail polish last 💅🏼.
- Acai requires you to adopt the feature.yaml format. I have written an introductory guide to writing these, and I have also provided a “spec for the spec” that will teach your agent how to convert your old specs to new feature.yaml files. If you can’t imagine moving past stream-of-consciousness prompting, this is not for you.
- Acai requires you to treat acceptance criteria as stable artifacts, with a stable identifier. These IDs create zero friction when drafting a new spec, but require a bit of extra care when changing an existing feature (you must re-align the code— it’s kindof the whole point). The feature.yaml synax supports
deprecatedandreplaced_byflags as well, if you want to maintain a complete spec history inline.
Roadmap
High-priority;- Some key readonly endpoints are missing, these will help agents coordinate with eachother.
- I need to finish realtime dashboard updates & presence (hell yeah Elixir + Phoenix!).
- I want to offer GitHub Actions or other CI recipes for better automation of the entire workflow.
- Augment specs right in the UI.
- Dispatch agents to respond to spec changes automatically.
- Plugins or MCP for OpenCode / Claude etc.
- Too many others to list here.